在数据可视化的众多工具中,堆积柱状图是一种极为有效的图表类型,尤其适用于展示不同类别数据的组成部分及其随时间或类别的变化趋势。本章将聚焦于如何利用Python进行数据处理,为绘制堆积柱状图做好充分准备。
一、堆积柱状图概述
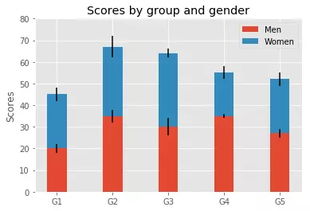
堆积柱状图通过在垂直或水平方向上堆叠多个数据系列来显示每个类别的总量,同时清晰地展示各组成部分的贡献比例。它不仅能比较各类别的总量,还能直观地看到各组成部分在类别间的差异。常见应用场景包括:
- 展示不同产品在各季度的销售构成。
- 比较多个地区在不同年份的人口结构变化。
- 分析公司各部门在不同项目的预算分配。
二、数据处理前的准备工作
在绘制堆积柱状图前,必须确保数据格式符合绘图库的要求。通常,我们需要将数据整理成以下结构:
- 索引或类别列:代表柱状图的横轴类别(如产品名称、年份、地区)。
- 系列列:代表堆叠的各个组成部分(如不同产品类型、人口年龄组、部门名称)。
- 数值列:对应每个类别和系列的具体数值。
三、数据处理核心步骤
1. 数据读取与清洗
使用Pandas库读取数据(如CSV、Excel文件),并进行初步清洗:`python
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 检查缺失值
df.isnull().sum()
# 填充或删除缺失值(根据实际情况)
df.fillna(0, inplace=True)`
2. 数据重塑
原始数据往往以“宽格式”存在,即每个系列作为单独的列。我们需要将其转换为适合堆积柱状图的“长格式”或直接使用宽格式进行绘图。以下是两种常见方法:
- 方法一:使用Pivot表(若数据为长格式,需转换为宽格式)`python
# 假设原始数据列为:'Category', 'Series', 'Value'
dfpivot = df.pivot(index='Category', columns='Series', values='Value')
dfpivot.fillna(0, inplace=True)`
- 方法二:直接聚合数据(若数据分散,需按类别和系列分组求和)`python
dfgrouped = df.groupby(['Category', 'Series'])['Value'].sum().unstack(fillvalue=0)`
3. 数据排序与筛选
为确保图表的可读性,可能需要对类别或系列进行排序或筛选:`python
# 按类别总量排序
dfpivot['Total'] = dfpivot.sum(axis=1)
dfpivot = dfpivot.sort_values('Total', ascending=False).drop('Total', axis=1)
# 筛选主要系列(如前5个)
topseries = dfpivot.sum().nlargest(5).index
dfpivot = dfpivot[top_series]`
4. 计算堆叠比例(可选)
若需显示百分比堆积柱状图,需将数据转换为比例:`python
dfpercentage = dfpivot.div(df_pivot.sum(axis=1), axis=0) * 100`
四、数据输出与验证
处理后的数据应保存为中间文件,并验证其结构:`python
# 保存处理后的数据
dfpivot.tocsv('processed_data.csv')
# 查看数据前几行
print(df_pivot.head())
# 检查数据形状和汇总统计
print(f'数据形状: {dfpivot.shape}')
print(dfpivot.describe())`
五、常见问题与解决策略
- 负值处理:堆积柱状图通常不适合包含负值的数据。若存在负值,考虑使用分组柱状图或对数据源进行调整。
- 类别过多:当类别或系列过多时,图表会显得杂乱。可通过聚合小类别(如“其他”项)或使用交互式图表解决。
- 颜色选择:为不同系列选择高对比度的颜色,确保堆叠部分清晰可辨。可使用配色工具(如ColorBrewer)生成调色板。
六、
数据处理是绘制高质量堆积柱状图的基础。通过Pandas进行有效的数据清洗、重塑和聚合,我们能将原始数据转化为可直接用于可视化的结构化数据。在后续章节中,我们将结合Matplotlib、Seaborn或Plotly等库,将处理好的数据绘制成直观的堆积柱状图,进一步揭示数据背后的故事。
通过本章的学习,您应已掌握为堆积柱状图准备数据的关键技能。记住,良好的数据处理习惯能极大提升可视化效果的分析价值和沟通效率。