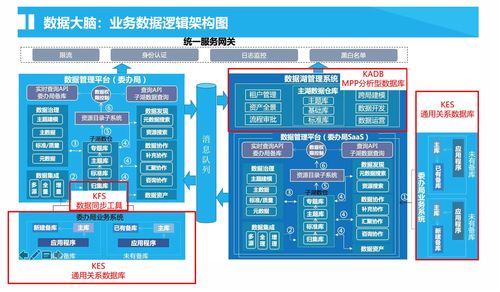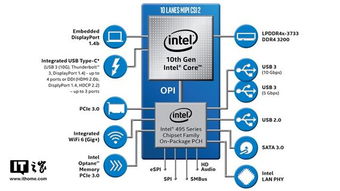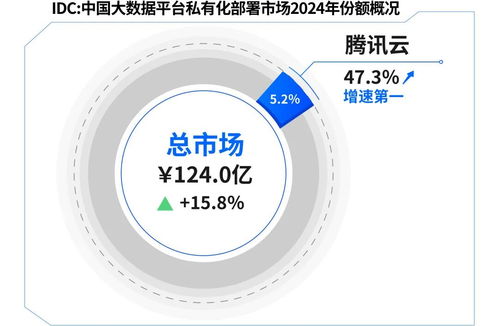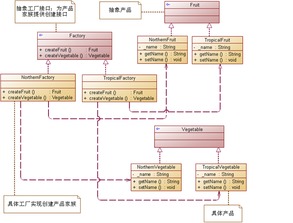
在数据分析领域,高效处理复杂数据源是关键挑战。抽象工厂模式作为工厂模式的进阶形式,为解决这一问题提供了优雅方案。
抽象工厂模式核心概念
抽象工厂模式通过创建相关或依赖对象的家族,而无需指定具体类。在数据分析场景中,这意味着我们可以创建统一的数据处理管道,适配不同数据源(如CSV、数据库、API等)。
Python实现示例
假设我们需要处理多种数据格式,可以通过抽象工厂实现:`python
from abc import ABC, abstractmethod
class DataProcessorFactory(ABC):
@abstractmethod
def createreader(self):
pass
@abstractmethod
def createcleaner(self):
pass
@abstractmethod
def create_analyzer(self):
pass
class CSVProcessorFactory(DataProcessorFactory):
def createreader(self):
return CSVReader()
def createcleaner(self):
return CSVCleaner()
def create_analyzer(self):
return CSVAnalyzer()`
在DataGuru社区的实际应用
DataGuru作为专业数据分析社区,推荐以下实践:
- 数据源扩展性:新数据源只需实现对应工厂类
- 代码复用:统一接口确保数据处理逻辑一致
- 维护便捷:修改特定数据源处理逻辑不影响其他组件
数据处理流程优化
通过抽象工厂模式,数据分析项目能够:
- 降低模块间耦合度
- 提高代码可测试性
- 支持动态数据源切换
- 便于团队协作开发
在实际项目中,结合pandas、numpy等库,抽象工厂模式显著提升了数据处理管道的灵活性和可维护性,是数据分析工程师值得掌握的设计模式。