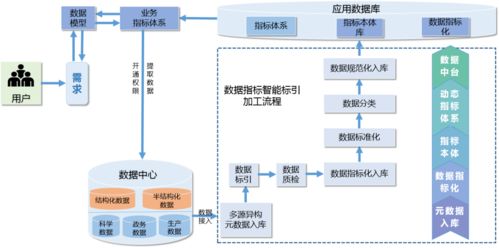
在知网大数据治理工具系统的整体架构中,数据处理是承上启下的核心环节。本篇将详细解析该系统的数据处理模块,包括数据清洗、数据转换、数据集成、数据脱敏等关键功能。
一、数据清洗功能
数据清洗模块提供智能化的数据质量检测与修复能力,支持:
- 格式校验:自动识别数据类型与格式规范,检测格式错误
- 缺失值处理:提供均值填补、众数填补、删除记录等多种处理策略
- 异常值检测:基于统计方法和机器学习算法识别异常数据
- 重复数据识别:通过相似度计算和规则匹配识别重复记录
二、数据转换功能
数据转换模块支持多种数据结构的转换与标准化:
- 格式转换:支持CSV、JSON、XML等多种数据格式互转
- 编码转换:自动处理字符编码问题,支持UTF-8、GBK等编码转换
- 数据类型转换:实现数值型、字符型、日期型等数据类型的自动转换
- 数据标准化:提供归一化、标准化等数据预处理方法
三、数据集成功能
该模块实现多源异构数据的无缝集成:
- 数据联邦:支持跨数据源的联合查询与访问
- ETL处理:提供可视化的ETL流程设计界面
- 实时数据接入:支持Kafka、Flume等流式数据接入
- API集成:提供RESTful API接口,便于系统间数据交换
四、数据脱敏与安全
为确保数据安全合规,系统提供:
- 敏感数据识别:基于规则和机器学习算法自动识别敏感信息
- 脱敏策略:支持掩盖、替换、泛化等多种脱敏方式
- 权限控制:细粒度的数据访问权限管理
- 操作审计:完整记录数据处理操作日志
五、性能优化特性
系统在数据处理性能方面具备以下优势:
- 分布式计算:基于Spark引擎实现大规模数据并行处理
- 内存计算:采用内存计算技术提升处理效率
- 智能调度:根据数据量和计算复杂度自动优化任务调度
- 缓存机制:建立多级缓存体系,减少重复计算
知网大数据治理工具系统的数据处理模块,通过上述功能的有机整合,为用户提供了高效、安全、智能的数据处理解决方案,有效支撑了后续的数据分析和应用环节。系统的可视化操作界面和丰富的API接口,使得数据处理工作更加便捷高效,大大提升了数据治理的整体效率。